Introduction to reinforcement learning
Jim Dai (iDDA, CUHK-Shenzhen)
See Slides and recorded Video for the lecture on youtube.
- MDP framework, Terminology, Bellman equation
- Markov Decision Process
- Bellman equation
- Bellman optimal equation
- Infinite horizon discounted problem
- Fix point iteration (Contraction mapping)
- Dynamic Programming
- Value iteration (VI)
- Policy iteration (PI)
- Policy Evaluation
- Policy Improvement
- Approximate PI
- Bellman Error
- Tabular TD(0)-learning
- Q-factor
- Q-learning as stochastic VI (off policy)
- optimistic PI for Q-factors: SARSA (on policy)
An overview of modern (Deep) Reinforcement Learning Algorithms:
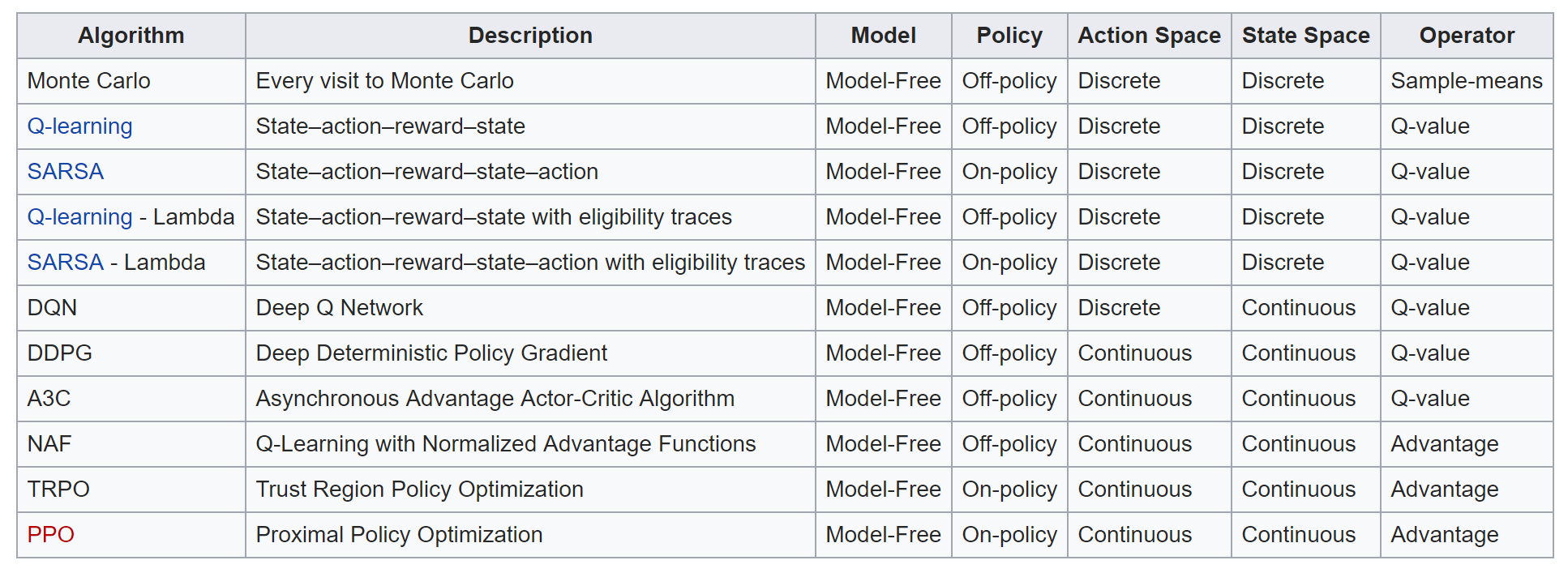
- Things not yet covered
- On-policy/Off-policy
- Safe exploration
Discuss in the google groups!